Introduction
Dynamo is used to manage the state of services that have very high reliability requirements and need tight control over the tradeoffs between availability, consistency, cost-effectiveness and performance.
Background
Store and retrieve data by primary key, but does not need complex querying and management functionality offered by an RDBMS.
System Assumptions and Requirements
Query Model
Simple read / write operations to data uniquely identified by a key. State is stored as binary objects. No operations span multiple tables and no need for relational schema.
ACID Properties
See ACID
Set of properties that guarantee that database transactions are processed reliably.
However, systems with ACID tend to have poor availability, hence, Dynamo operate with weaker consistency.
Service Level Agreements
See SLA
300ms for 99.9% of requests for a peak client load of 500 requests/sec.
Design Considerations
Conflict resolution is on read to ensure that writes are never rejected.
Other key principles:
Incremental scalability
Should be able to scale out one storage host at a time.
Symmetry
Every node should have the same set of responsibilities as its peers
Decentralization
No centralized control, more peer-to-peer techniques
Heterogeneity
Work distribution must be proportional to the capabilities of the individual servers.
Related Work
TO READ
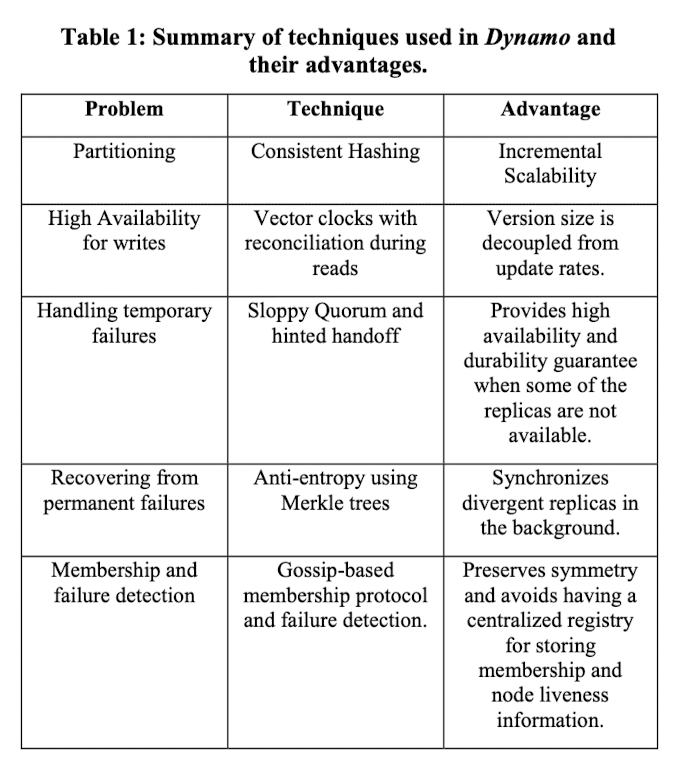
System Architecture
System Interface
get(key)put(key, context, object)
Context encodes system metadata about the object such as object’s version.
Partition Algorithm
Relies on consistent hashing (output range is treated as a fixed circular space).
Each node is assigned a random value within this space. And each data item is hashed by its key and walks clockwise to find the first node larger than its position.
Advantage: departure of a node only affect its immediate neighbours
Disadvantage: Non-uniform data and load distribution.
Solution: each node is assigned to multiple points in the ring, virtual nodes.
- if a node becomes unavailable, the load is evenly dispersed across the remaining nodes.
- when a node comes back, it accepts a roughly equivalent amount of load from each other available nodes.
Replication
Each data item is replicated at N hosts (which can be configured). Each key k is assigned to a coordinator node. The coordinator is responsible for the replication of the data items. The data is replicated to the N - 1 clockwise successor nodes in the ring. (must be distinct physical nodes)
The list of nodes responsible for storing a key is called the preference list.
Data Versioning
Updates are replicated asynchronously. Hence reads might get back non up-to-date data.
Each modification is treated as a new and immutable version of the data, and multiple versions can be present at the same time. If conflicts happen, the client does the reconciliation.
Dynamo also uses vector clocks to capture causality between versions of the same object.
When a client wishes to update an object, it must specify which version.
Execution of get() and put() operations
Let R be the minimum number of nodes that must participate in a successful read operation and W be the minimum number of nodes that must participate in a successful write operation.
And R + W > N (sloppy quorum)
For a put() request, the coordinator generates the vector clock and writes the new version locally. It then sends the new data to the N highest-ranked reachable nodes, and when at least W - 1 nodes responds, the write is considered successful.
Same for get() request.
Handling Failures: Hinted Handoff
If a node is down, the replica will be sent to the next node, and it will have a hint in its metadata to suggest the intended recipient of the replica. When it comes back, the data is sent back.
This ensures that read/write operations are not failed due to temporary node or network failures.
Handling permanent failures: Replica synchronization
If hinted replicas also become unavailable, a replica-synchronization protocol is implemented.
Merkle trees - hash trees where leaves are hashes of the values of individual keys and parent nodes are hashes of their children.
Each branch can be checked without the entire tree. (decreases the amount of data transferred)
Each node maintains a separate Merkle tree for each key range and two nodes exchange the Merkle tree corresponding to the key range that they host in common.
Membership and Failure Detection
Ring Membership
Gossip-based protocol is used to propagate membership changes and maintains an eventually consistent view of membership. Each node contacts a peer chosen at random every second and the two nodes efficiently reconcile their persisted membership change histories.
External Discovery
To prevent cases where there are two group of nodes not knowing each other called logical partition, Dynamo uses seeds, which are nodes that are known to all nodes.
Failure Detection
A node can be considered failed if it does not respond to one’s message