3 - Implementation
Many different implementations, but at Google
- Dual-processors machines, 2-4GB of memory
- Commodity networking hardware is used
- Cluster consists of hundreds or thousands of machines, failures are common
- Storage provided by inexpensive IDE disks
- Jobs submitted to scheduling system
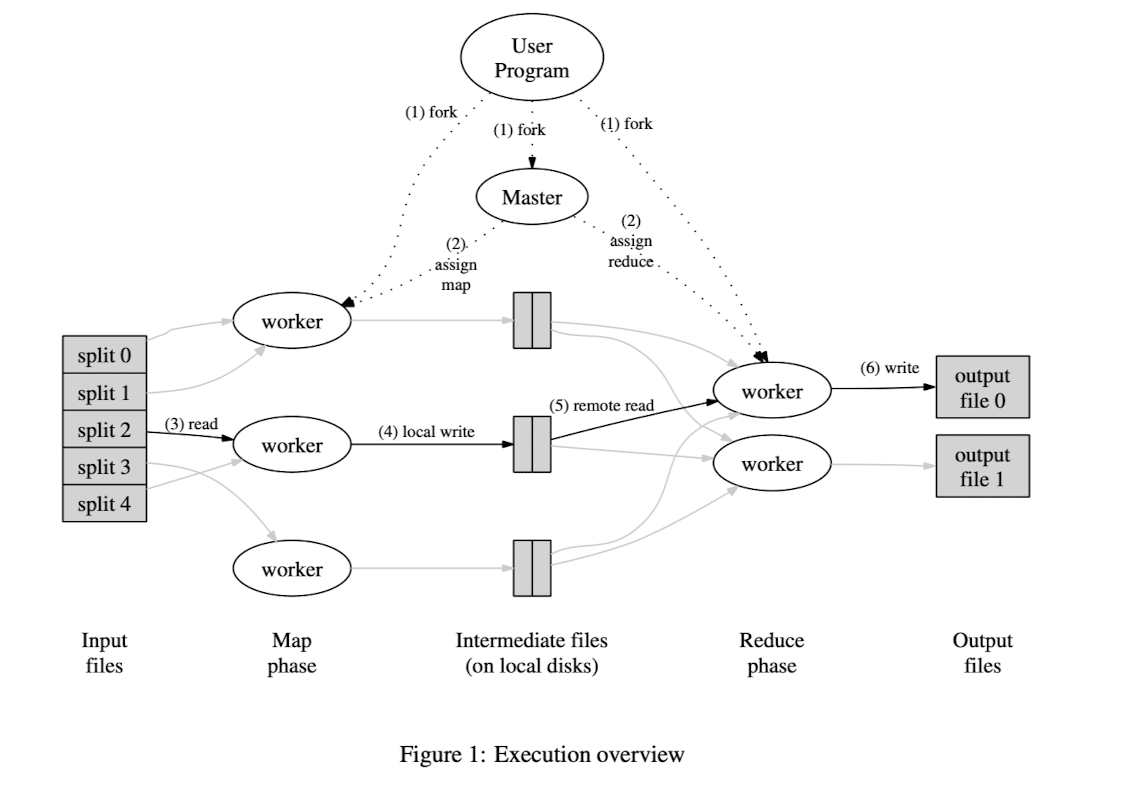
Execution Overview
Input data splitted into M splits, they can be processed in parallel by different machines. Reduce functions are distributed by partitioning the intermediate key space into R pieces using a partitioning function, R is specified by the user.
Steps
- Input files splitted into M pieces (each 16 to 64MB).
- One program is the master, it picks idle workers and assign them work, M map tasks and R reduce tasks.
- For a map task, it reads content from the input data, and pass them to the map function, result buffered in memory
- Periodically they are written to disk, partitioned, and the locations are passed back to the master, who forwards them to the reducers
- After the reduce worker is notified about these locations, it uses RPCs to read the data from disk. After it gets all the data, intermediate keys are sorted.
- For each key and its corresponding values, they are passed to the reduce function and the result is appended to a final output file
- Done after all map tasks and reduce tasks are done.
There are R final output files.
Mappers store their output locally, reducers store their output in a global file system.
Master Data Structures
For each task, the state is stored IDLE, IN-PROGRESS, COMPLETED
Fault Tolerance
Worker Failure
Workers are pinged by the master periodically.
Any tasks (in progress or completed) from a failed worker are reset back to their initial idle state.
Master Failure
Write periodic checkpoints of the master data structure, if it dies, a new copy can be started from the last checkpoint.
Or the job can abort is the master fails and retry again.
Semantics in the Presence of Failures