Widely developed within Google
Introduction
Main goals:
- Performance
- Scalability
- Reliability
- Availability
Component failures are the norm rather than the exception
Files are huge by traditional standards, multi-GB files are common
Most files are updated by appending new data instead of overwriting existing data.
Design Overview
Assumptions
- Built from many inexpensive commodity that often fail
- Large files
- Large streaming reads and small random reads
- Large sequential writes (append)
- Concurrency
- High sustained bandwidth
Interface
Files are organized hierarchically and identified by pathnames.
Architecture
Single master and multiple chunkservers and is accessed by multiple clients.
Files are divided into fixed-size chunks. Each chunk is identified by an immutable and globally unique 64-bit chunk handle assigned by the master.
For reliability, each chunk is replicated on numerous chunkservers.
The master contains all file system metadata (mapping from files to chunks, locations of chunks). The master also periodically communicates with chunkservers in HeartBeat messages to give instructions and collect its state.
No caching! Because apps stream through huge files or files are too huge to be cached.
Single Master
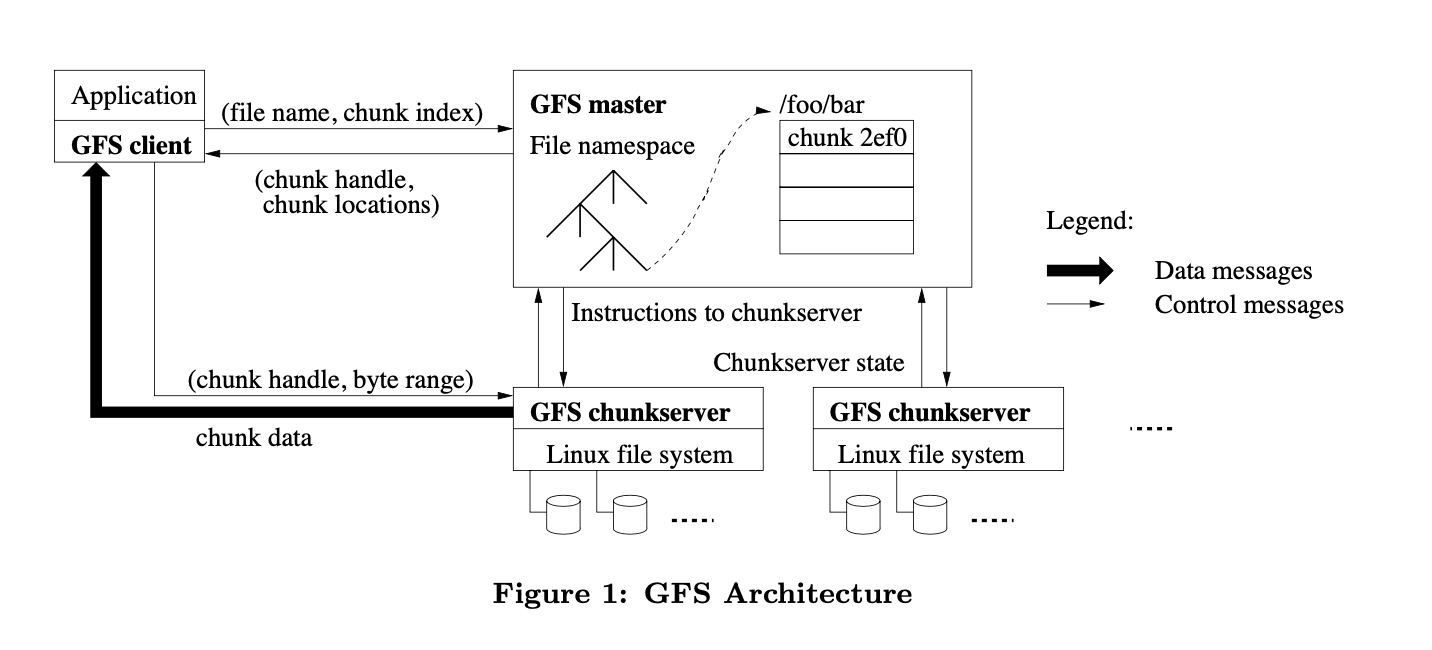
Clients never read and write file data through the master.
Client asks master for chunkservers it should contact and contact chunkservers directly.
Chunk Size
64MB, and they are stored as plain Linux file on chunkservers.
Larger file size less interaction between client and master / more operations on the chunk reducing network overhead / reduces metadata size on the master
Metadata
- File and chunk namespaces
- Mapping from file to chunks
- Locations of each chunk
Everything is stored in master’s memory. However, the first two types are also kept persistent in an operation log on disk.
In-Memory Data Structures
Memory of the master node is not really a concern because we only need ~64 bytes of metadata per chunk.
Chunk Locations
During startup, the master asks each chunkserver for the chunks they stored. Later on, this is done via HeartBeat messages.
Operation log
Only persisted record of metadata.
Logical timeline defining the order of concurrent operations.
Replicated on multiple remote machines.
Consistency Model
Guarantees by GFS
Namespace mutations are atomic.
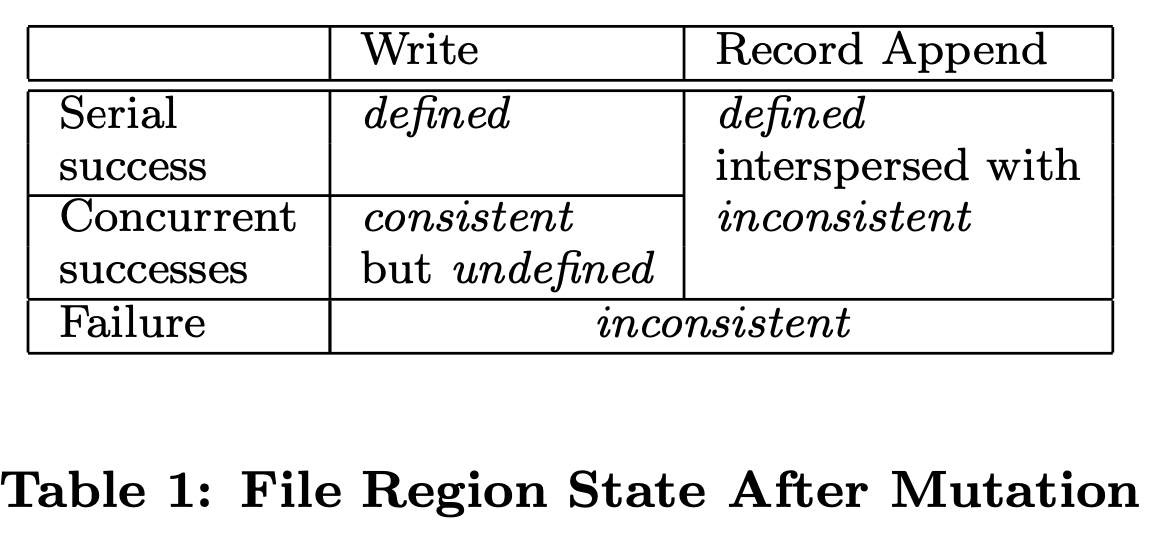
Consistent: all clients will always see the same data (no matter the replica) Defined: consistent and that clients will see mutations writes in its entirety.
Implications for Applications
Most is appending, checkpoints how much has been successfully written.
Readers and process up to the last checkpoint.
Use checksums to identify and discard extra padding and record fragments
System Interactions
Minimize master’s involvement
Leases and Mutation Order
Each mutation is performed at all the chunk’s replicas. Leases are used to maintain a consistent mutation order across replicas.
The master grants a lease to a replica called the primary. The primary picks a serial order for all mutations to the trunk.

- Client asks master which chunkserver holds the current lease, if no one has the lease, master chooses a replica and grants the lease
- Master replies with the identity of the primary replica and the location of the other replicas.
- Client pushes the data to all replicas, can be done in any order, data is stored in replica’s LRU cache.
- Client sends write requests to primary after all replicas acknowledged they received the data.
- Primary forwards write request to all replicas
- Reply to primary
- Replies to client, any errors are reported to the client.
Data Flow
Data is pushed linearly along a chain of chunkservers to maximize bandwidth usage.
Once a chunk server receives some data, it starts forwarding immediately.
Atomic Record Appends
Atomic append operation record append
GFS does not guarantee that all replicas are bytewise identical, it only guarantees that the data is written at least once as an atomic unit.
Snapshot
Makes a copy of a file or a directory (almost instantaneously)
- Revoke any outstanding leases
- Log the operations on disk
- After snapshotting, if client wants to write to a chunk C, master creates chunk C’ and asks every replica who currently have C to create C’ (less network overhead since on same servers )
Master Operation
Namespace Management and Locking
Namespace is represented as a lookup table mapping full pathnames to metadata (prefix compression is used)
Use read-write locks
Replica Placement
- Maximize data reliability and availability
- Maximize network bandwidth utilization
Try to spread replicas across racks
Creation, Re-replication, Rebalancing
Creation:
- Choose replicas with below-average disk utilization
- Limit the number of recent creations on each server
- Spread replicas across racks
Re-replication:
A chunk is re-replicated as soon as the number of available replicas fall below a user-specified goal.
Rebalancing:
Done periodically, moves replicas for better disk space and load balancing.
Garbage collection
After file is deleted, storage reclaim is done lazily during garbage collection
TO READ
High Availability
Fast Recovery
Master and chunkservers are designed to restore in seconds.
Chunk Replication
Default is 3 replicas, but can be specified by user.
Master replication:
Master state is replicated
Data Integrity
Each chunk is broken up to 64KB blocks and each block has a corresponding checksum.