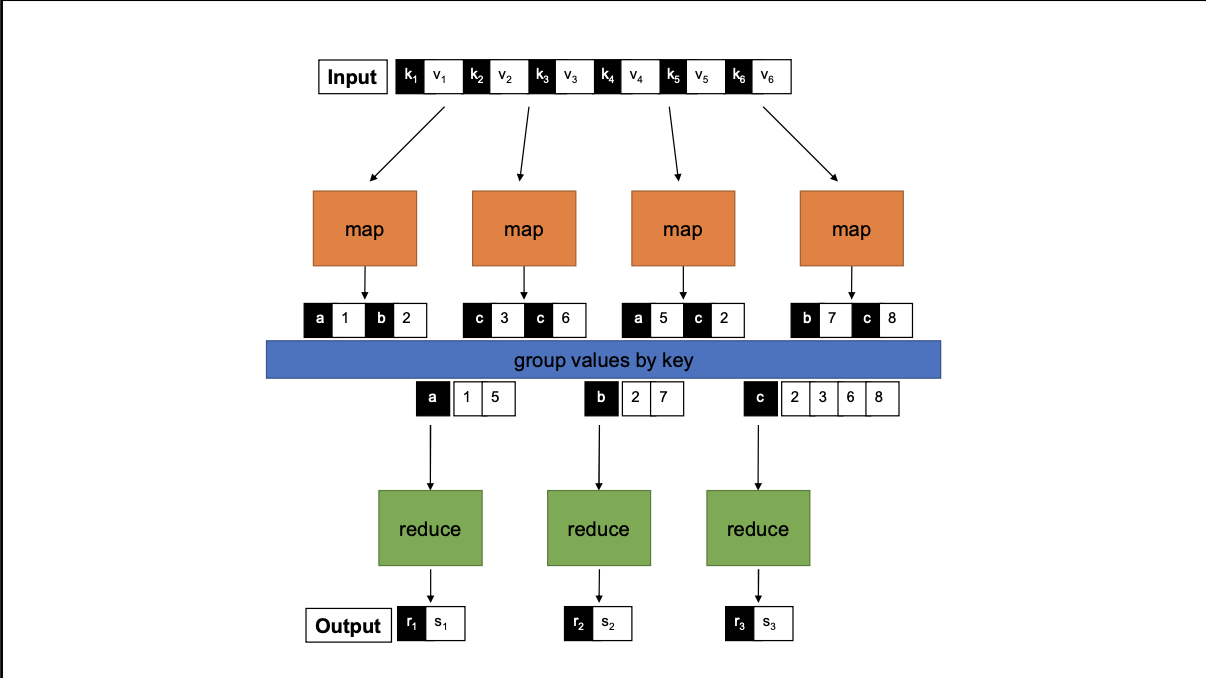
Based around key-value pairs. If the input is a text file, key = position of a line and value = text
Two functions
map: (k1,v1) => List[(k2, v2)]reduce: (k2, List[v2]) => List[(k3, v3)]
Example for Word Count
def map(line):
for word in line:
emit(word, 1)
def reduce(key, values):
sum = 0
for v in values:
sum += v
emit(key, sum)We can also have multiple reducers and each reducer gets ALL pairs for a given key
Optional: define third function, partitioner
partition: (k2, v2, n) -> [0, n)
Apache Hadoop is the famous open-source implementation of MapReduce/
Framework:
- Assign workers to map and reduce tasks
- Divides data between map workers
- Group intermediate values, sorting pairs by key
- Handle errors
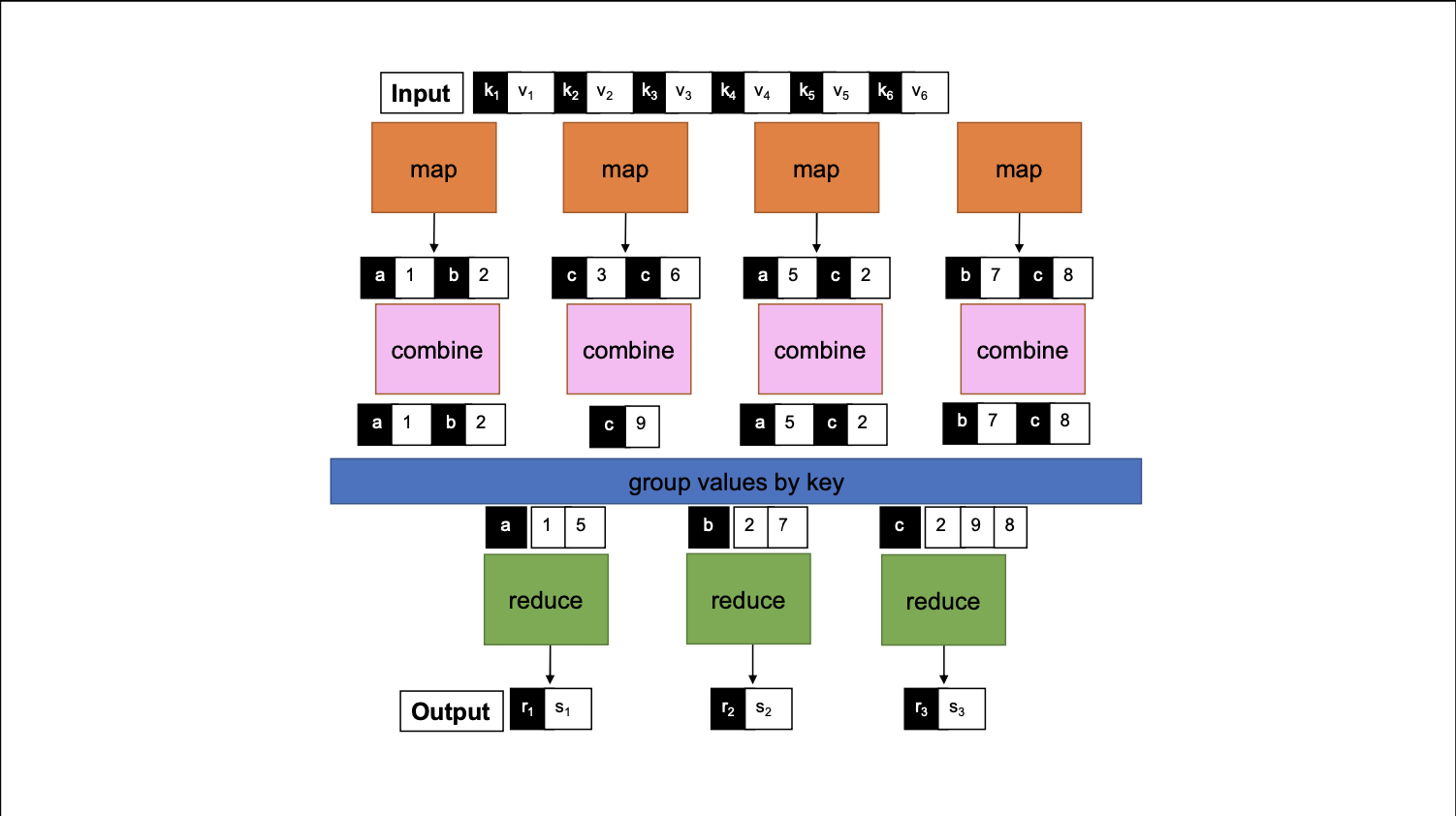
Optional: additional function combiner
combine: (k2, List[v2]) => List[(k2, v2)]
Map side:
- map outputs are buffered in memory (circular buffer)
- when full, spilled to disk into R intermediate files
Hadoop Distributed File System (HDFS)
- Very large, millions of files
- Assume commodity hardware
- Optimized for batch processing
Very similar to GFS
NameNode (similar to GFS master node):
- manages file system namespace
- maps filename to set of blocks
- maps blocks to the DataNodes where it resides
- cluster configuration management
- replication engine for blocks
DataNode:
- block server
- stores data in the local file system
- stores metadata of a block
- servers data and metadata to clients
- periodically sends a report of all existing blocks to NameNode
- pipelining => forwards data to other specified DataNodes
Policy:
- 3 replicas will be stored on at least 2 racks.
- client reads from nearest replica.
Hadoop Cluster Architecture
Use SAN (Storage Area Network) to get data to the workers.
- not optimal because of high communication costs
Solution:
- move workers to the data, co-locate storage and compute.
- when assigning tasks to servers, considers which servers contain what part of the file to minimize copy over network
Combiners
Have same signature as reducers.
They are optional
- may not be run
- may run once
- may run many times
They improve performance by reducing network traffic
In-Mapper Combine
In-memory combiner Pros: speed Cons: requires memory management